
Top row: Two input frames. Bottom row: Our generated results. More results





Top row: Two input frames. Bottom row: Our generated results. More results






Top row: Two input frames. Bottom row: Our generated results.





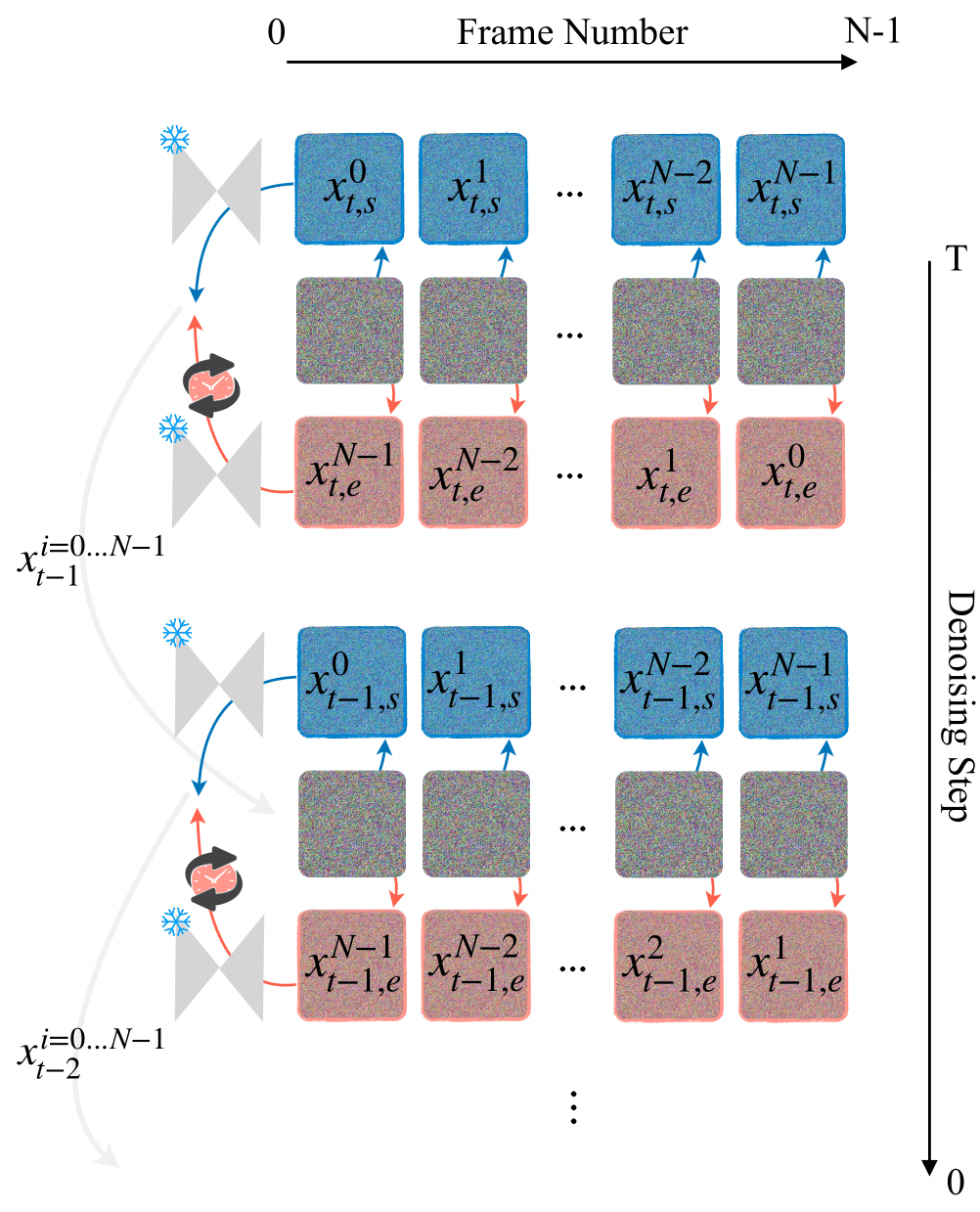
We introduce bounded generation as a generalized task to control video generation to synthesize arbitrary camera and subject motion based only on a given start and end frame. Our objective is to fully leverage the inherent generalization capability of an image-to-video model without additional training or fine-tuning of the original model. This is achieved through the proposed new sampling strategy, which we call Time Reversal Fusion, that fuses the temporally forward and backward denoising paths conditioned on the start and end frame, respectively. The fused path results in a video that smoothly connects the two frames, generating inbetweening of faithful subject motion, novel views of static scenes, and seamless video looping when the two bounding frames are identical. We curate a diverse evaluation dataset of image pairs and compare against the closest existing methods. We find that Time Reversal Fusion outperforms related work on all subtasks, exhibiting the ability to generate complex motions and 3D-consistent views guided by bounded frames.


Dynamics Bound: Input (left), FILM-Net (middle), Ours (right). More Comparisons

The authors would like to thank Tsvetelina Alexiadis, Taylor McConnell, and Tomasz Niewiadomski for the great help with perceptual user study. Special thanks are also due to Liang Wendong, Zhen Liu, Weiyang Liu, Zhanghao Sun, Yuliang Xiu, Yao Feng, Yandong Wen for their proofreading and insightful discussions